

Table of Links
3 Method and 3.1 Phase 1: Taxonomy Generation
3.2 Phase 2: LLM-Augmented Text Classification
4 Evaluation Suite and 4.1 Phase 1 Evaluation Strategies
4.2 Phase 2 Evaluation Strategies
5.3 LLM-Augmented Text Classification
5.4 Summary of Findings and Suggestions
6 Discussion and Future Work, and References
5.4 Summary of Findings and Suggestions
We have shown that our novel TnT-LLM framework is capable of generating high-quality label taxonomies from unstructured text corpora with very little human instruction or intervention. In our evaluation of this approach on real-world AI chat conversations, we demonstrated that it can be used to find structure and organization in unstructured text. Our method outperforms the conventional embedding-based clustering approach, especially when deeper reasoning beyond surface-level semantics is required. Finally we found that while embedding-based clustering can still be effective, it is
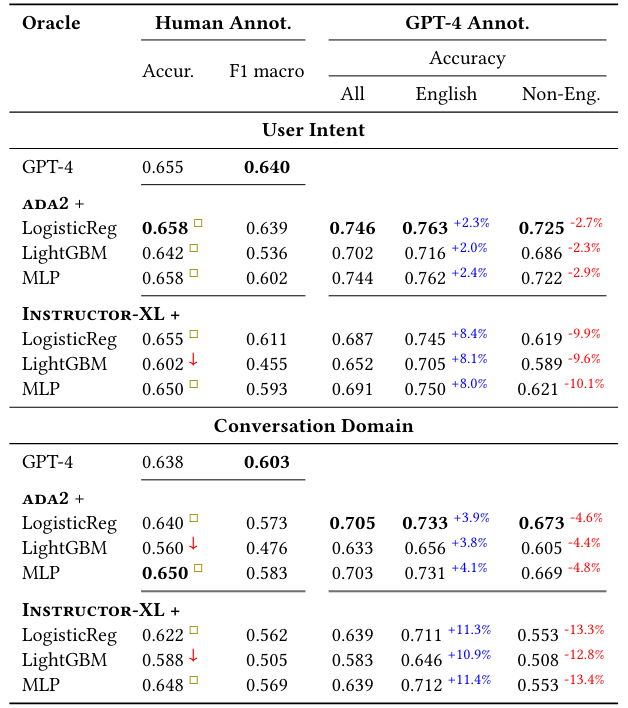
more susceptible to modeling choices or artifacts, such as cluster granularity and alignment of use-case with inputs.
We further explored the use of LLMs as raters or evaluators, demonstrating that they effectively approximate the collective opinion of humans on some evaluation tasks. Additionally, we found that LLMs excel at single-choice questions (e.g., pairwise label accuracy evaluation task) where they are forced to indicate preference on one option over another, but they can struggle on multiple-choice questions that involve subjective and nuanced judgments with implicit standards. We suggest using LLMs as an alternative strategy for human evaluation, but with caution and verification by measuring agreement with human preferences.
Lastly, we proposed a perspective of using LLMs as “annotators” rather than classifiers, harnessing their ability to create abundant data. By utilizing LLMs to generate pseudo labels for unlabeled data, we can distill a lightweight classifier that can be reliably deployed at scale. In our experiments, such a classifier achieved competitive results, and matched or even surpassed the performance of GPT-4
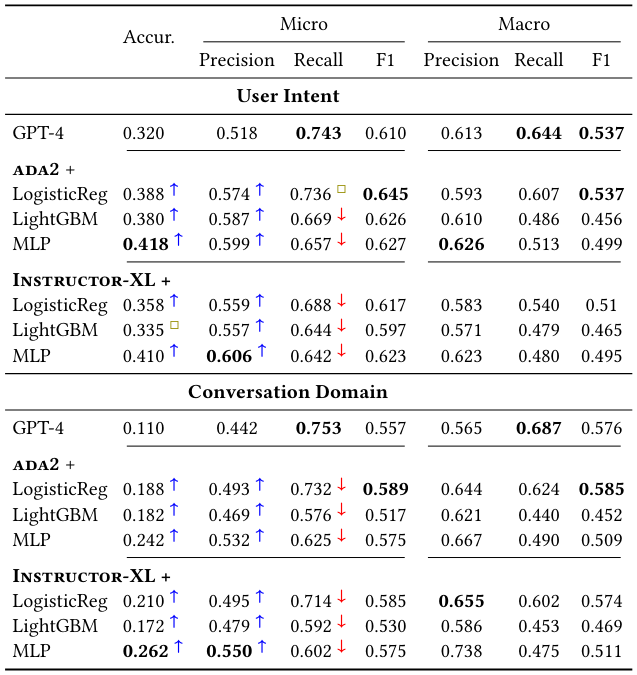
as a classifier. We advocate for a careful assessment of the potential use cases of LLMs, balancing performance and efficiency, while exploiting both their power to generalize with the maturity, speed, and cost of conventional machine learning classifiers.
This paper is available on arxiv under CC BY-NC-ND 4.0 DEED license.
Authors:
(1) Mengting Wan, Microsoft Corporation and Microsoft Corporation;
(2) Tara Safavi (Corresponding authors), Microsoft Corporation;
(3) Sujay Kumar Jauhar, Microsoft Corporation;
(4) Yujin Kim, Microsoft Corporation;
(5) Scott Counts, Microsoft Corporation;
(6) Jennifer Neville, Microsoft Corporation;
(7) Siddharth Suri, Microsoft Corporation;
(8) Chirag Shah, University of Washington and Work done while working at Microsoft;
(9) Ryen W. White, Microsoft Corporation;
(10) Longqi Yang, Microsoft Corporation;
(11) Reid Andersen, Microsoft Corporation;
(12) Georg Buscher, Microsoft Corporation;
(13) Dhruv Joshi, Microsoft Corporation;
(14) Nagu Rangan, Microsoft Corporation.