
Table of Links
-
- Classification Target
- Masked Conditional Density Estimation (MaCoDE)
-
- With Missing Data
-
- Related Works
- Conclusions and Limitations
- References
-
- A2 Proof of Proposition 1
- A3 Dataset Descriptions
-
- A5 Experimental Settings for Reproduction
A.7 Detailed Experimental Results
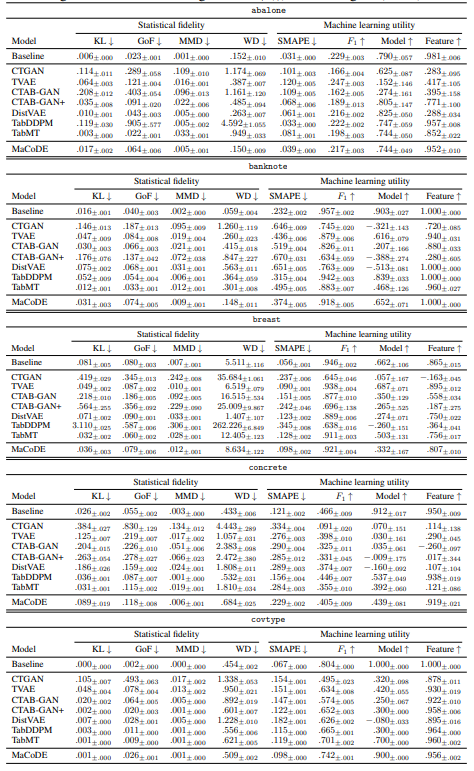
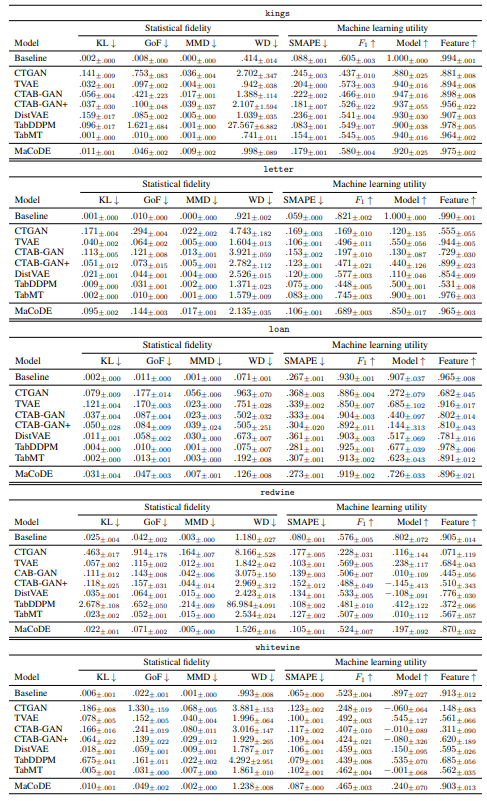
A.7.1 Q1. Synthetic Data Quality
A.7.2 Q1. Visualization of Marginal Histogram
Figure 7: Histograms of observed dataset and synthetic dataset, generated by MaCoDE.





Figure 8: Histograms of observed dataset and synthetic dataset, generated by MaCoDE.





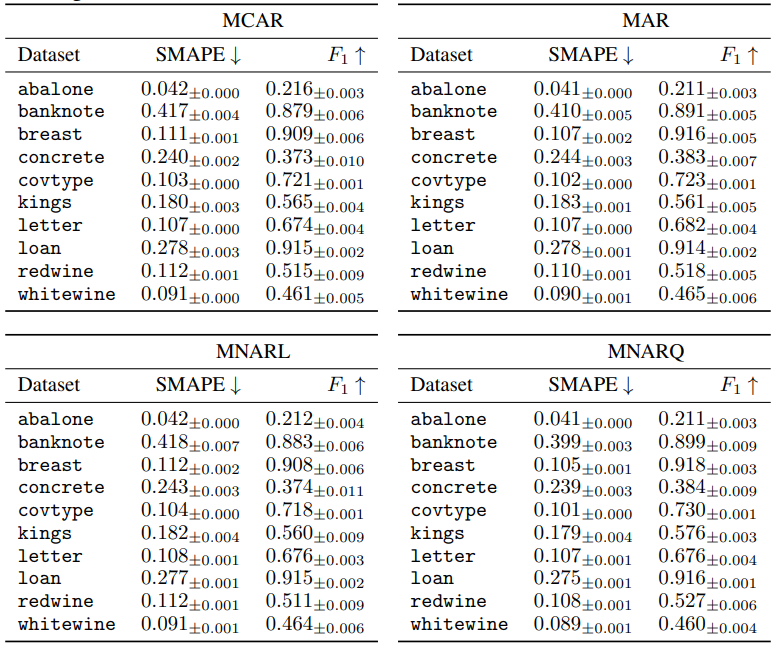
A.7.3 Q2: Synthetic Data Quality in Scenarios with Incomplete Training Dataset
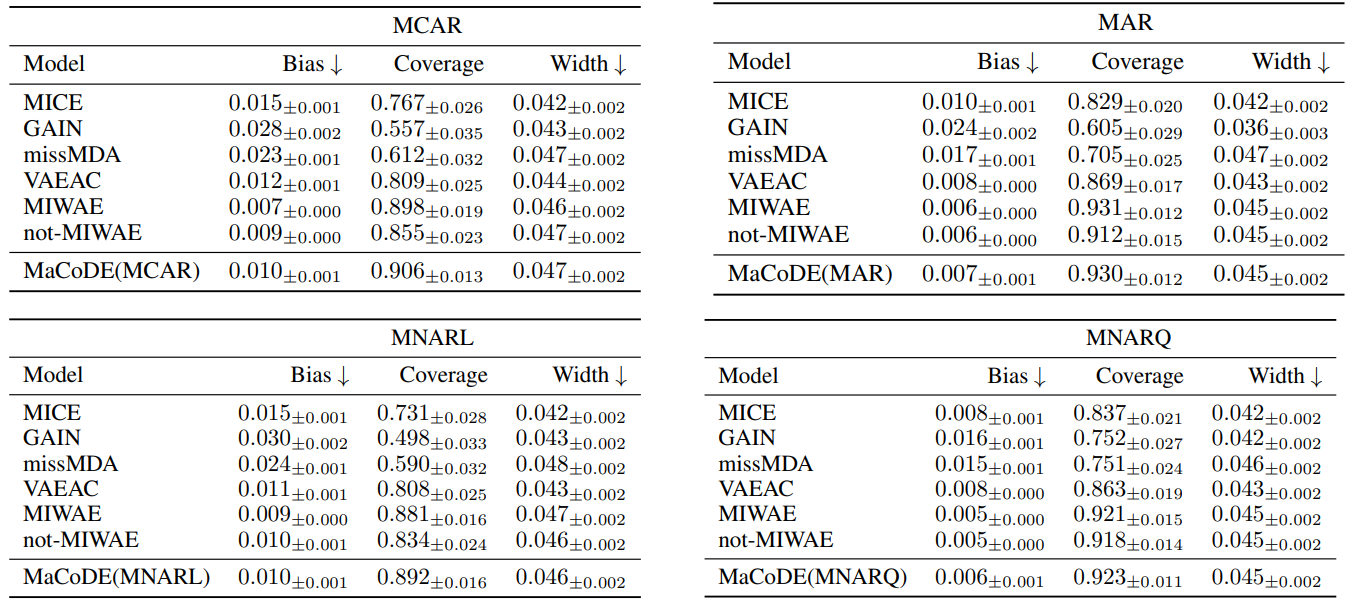
A.7.4 Q3: Multiple Imputation Performance
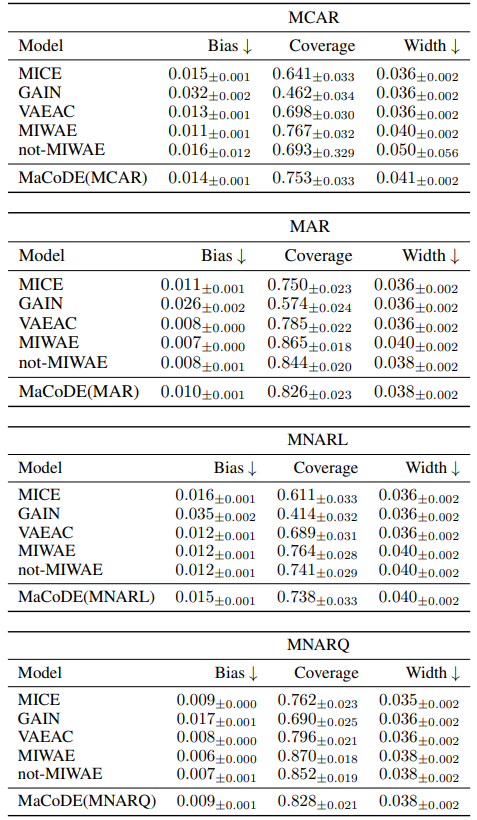

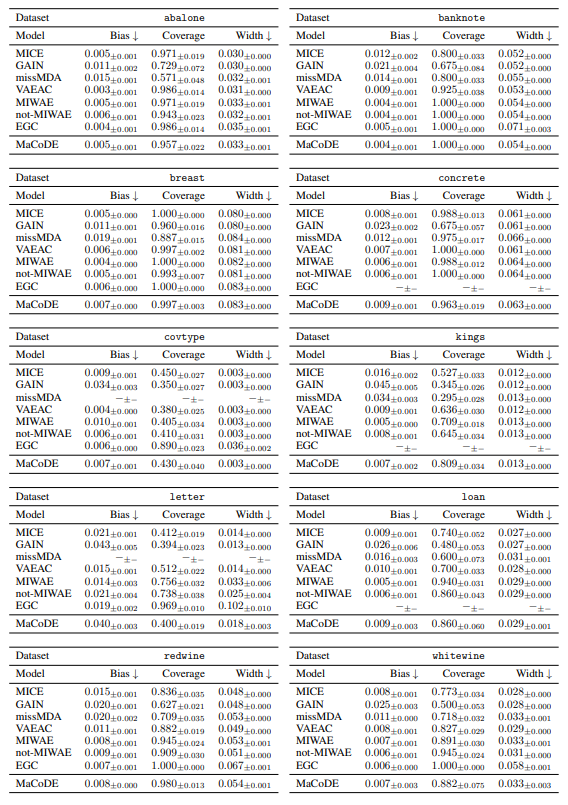

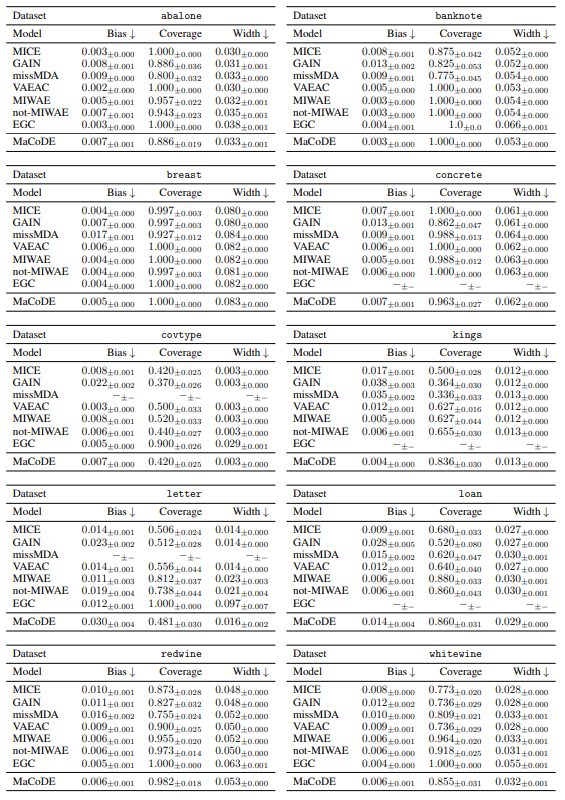
A.7.5 Q3: Multiple Imputation Performance of missMDA
A.7.6 Q3: Multiple Imputation Performance of EGC

Authors:
(1) Seunghwan An, Department of Statistical Data Science, University of Seoul, S. Korea ([email protected]);
(2) Gyeongdong Woo, Department of Statistical Data Science, University of Seoul, S. Korea ([email protected]);
(3) Jaesung Lim, Department of Statistical Data Science, University of Seoul, S. Korea ([email protected]);
(4) ChangHyun Kim, Department of Statistical Data Science, University of Seoul, S. Korea ([email protected]);
(5) Sungchul Hong, Department of Statistics, University of Seoul, S. Korea ([email protected]);
(6) Jong-June Jeon (corresponding author), Department of Statistics, University of Seoul, S. Korea ([email protected]).
This paper is